Use case
INRA
Publication of bibliographic records in the web of data
The [ProdInra] portal (http://prodinra.inra.fr/) is the search tool that provides access to the productions of the [Institut National de la Recherche Agronomique] (http://inra.fr/), in particular to the records of articles written by the institute's researchers. INRA wishes to study the dissemination of the metadata contained in this database, with several objectives in mind:
- publication of the metadata in compliance with Web of Data best practices;
- adding links to INRA's internal repositories (research structures, centers/departments/units, research activities, people, thematic fields), currently accessible via separate internal web services;
- adding links to external repositories, using text-mining tools:
- Agrovoc](http://aims.fao.org/fr/agrovoc)
- Gene ontology](http://geneontology.org/)
- Genomic and genetic databases
- Offer more intelligent search and visualization functions
An initial prototype for this study was produced using the VIVO tool.

VIVO is an open-source platform for disseminating and managing scientific publications, researcher profiles, research laboratories, and information on conferences and scientific events (see the blog post dedicated to it). VIVO is entirely based on semantic technologies (RDF, SPARQL, OWL), natively integrates raw data dissemination functionalities in RDF via URIs, and its screens are configurable via an ontology. VIVO also natively integrates data visualization functionalities.
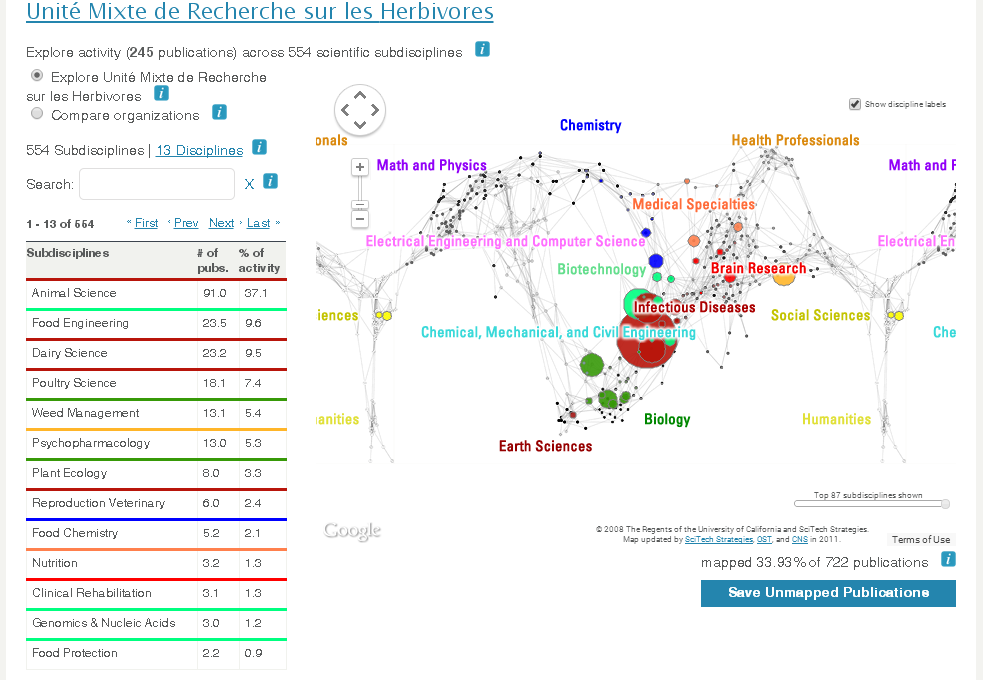
Initially, on behalf of INRA, we carried out several customized training days on the issues, standards and technologies of the web of data. Following this initial training, we implemented the migration of data from the ProdInra database and internal repositories to RDF data compatible with the VIVO ontology. This transformation, based on SOAP web service calls and XSLT transformation sheets, generated several RDF data files which were then imported into VIVO. We also produced an extension of the VIVO ontology specifically for INRA's needs, presented here at the semweb.pro conference.
In this phase of the project, VIVO made it possible to achieve a rapid prototyping of a result, natively proposing interesting data visualizations. This prototype will be used to demonstrate and explain the benefits of disseminating and linking bibliographic records in the Web of Data, and thus enhancing their value.
Back to the list of use cases