Etude de cas
INRA
Publication de notices bibliographiques dans le web de données
Le portail ProdInra est l'outil de recherche qui donne accès aux productions de l'Institut National de la Recherche Agronomique, en particulier aux notices d'articles écrits par les chercheurs de l'institut. L'INRA souhaite étudier la diffusion des métadonnées contenues dans cette base, avec plusieurs objectifs :
- la publication des métadonnées en respectant les bonnes pratiques du web de données;
- l'ajout de liens vers des référentiels internes à l'INRA (structures de recherche centres/départements/unités, activités de recherches, personnes, champs thématiques), aujourd'hui accessibles via des web services internes séparés;
- l'ajout de liens vers des référentiels externes, en s'aidant d'outils de text-mining :
- Agrovoc
- Gene ontology
- Banques de données génomiques et génétiques
- Offrir des fonctions de recherche et de visualisation plus intelligentes
Un premier prototype dans le cadre de cette étude a été réalisé à l'aide de l'outil VIVO.

VIVO est une plate-forme open-source qui permet la diffusion et la gestion des publications scientifiques, des profils de chercheurs, de laboratoires de recherche, et d'informations sur les conférences, les événements scientifiques (voir le billet de blog qui y est consacré). VIVO est entièrement basé sur les technologies sémantiques (RDF, SPARQL, OWL), intègre nativement les fonctionnalités de diffusion des données brutes en RDF via les URIs, et ses écrans sont configurables via une ontologie. VIVO intègre également nativement des fonctionnalités de visualisation de données.
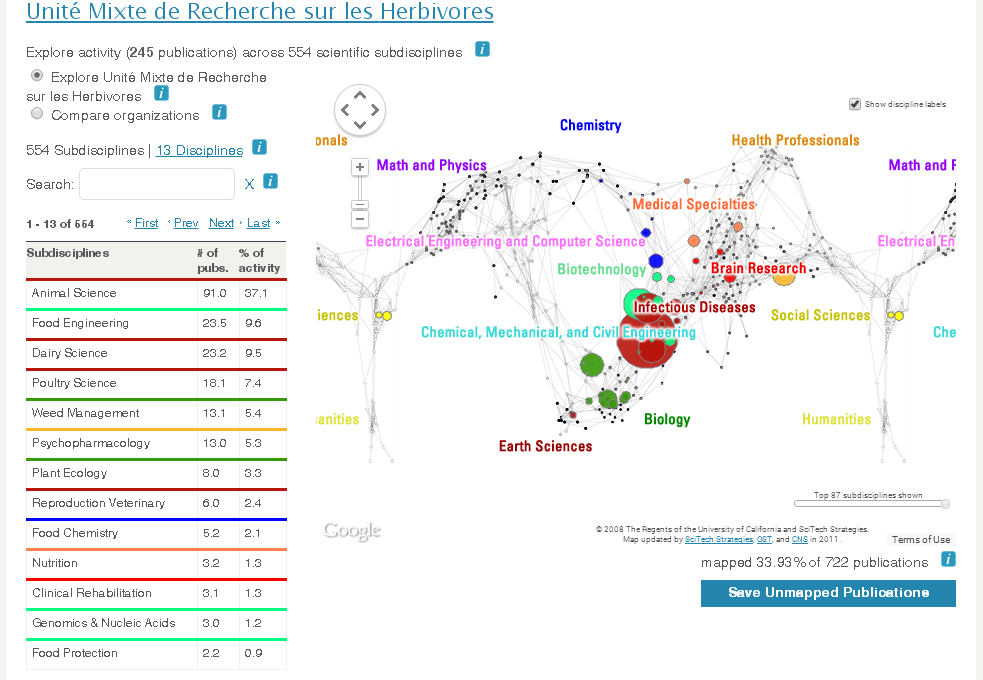
Dans un premier temps nous avons réalisé pour le compte de l'INRA plusieurs journées de formation sur-mesure sur les enjeux, les standards et les technologies du web de données. Suite à ces formations initiales nous avons implémenté la migration des données de la base ProdInra et des référentiels internes vers des données RDF compatibles avec l'ontologie VIVO. Cette transformation, basée sur des appels de web-service SOAP et des feuilles de transformation XSLT, a permis de générer plusieurs fichiers de données RDF qui ont été ensuite importés dans VIVO. Nous avons également réalisé une extension de l'ontologie VIVO spécifiquement pour les besoins de l'INRA, présentée ici lors de la conférence semweb.pro.
VIVO a permis dans cette phase du projet d'arriver à un prototypage rapide d'un résultat, proposant nativement des visualisations de données intéressantes. Ce prototype va permettre de démontrer et d'expliquer l'intérêt de la diffusion et de la mise en lien des notices bibliographiques dans le web de données pour leur valorisation.
Revenir à la liste des références